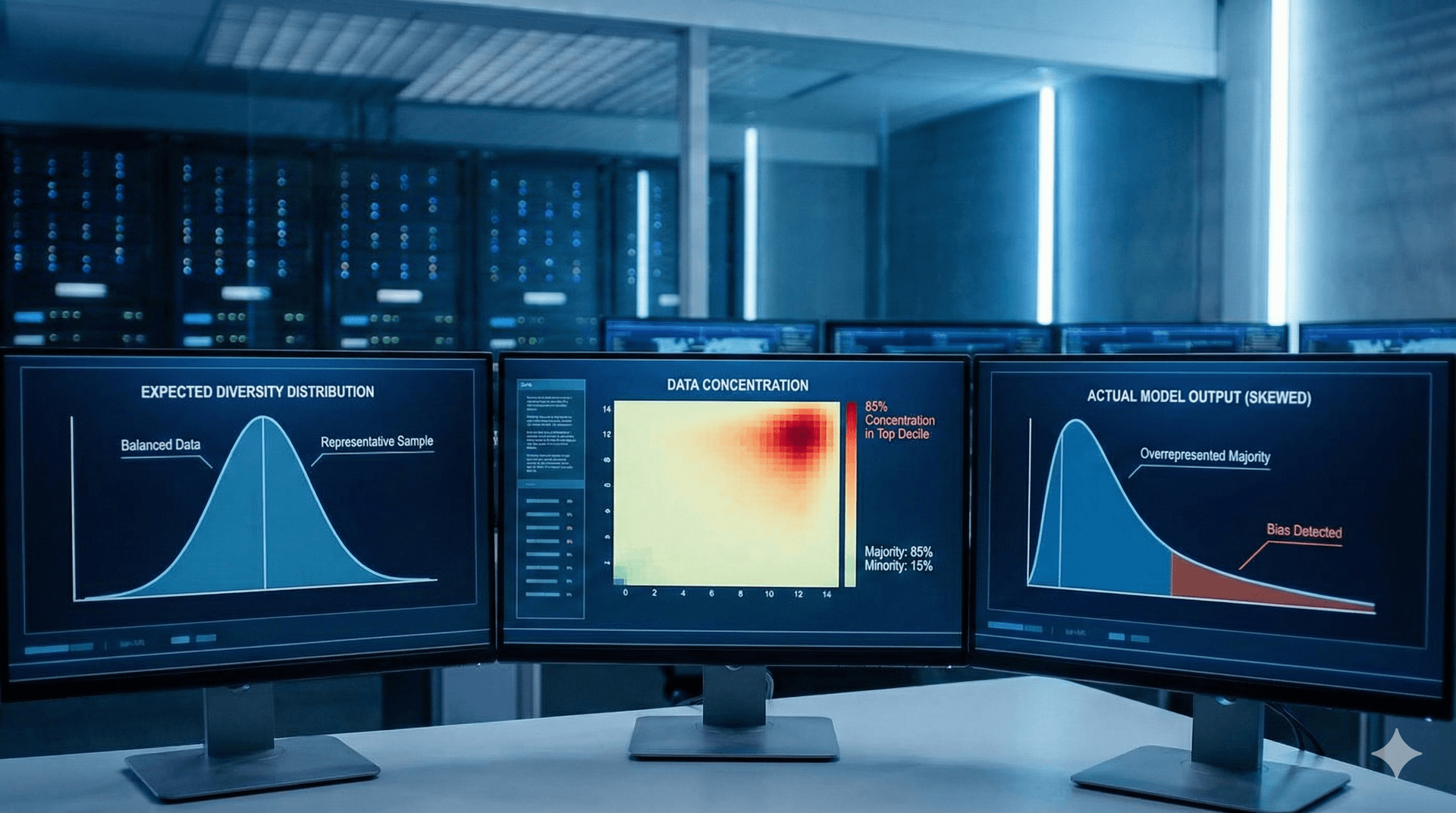
Bias (deutsch: Verzerrung, Voreingenommenheit) bezeichnet systematische Tendenzen in den Ausgaben eines Large Language Models, die bestimmte Gruppen, Perspektiven oder Darstellungen bevorzugen oder benachteiligen. Diese Verzerrungen stammen aus den Trainingsdaten und spiegeln gesellschaftliche Vorurteile wider.
Wichtig: LLMs sind nicht "boeswillig" - sie reproduzieren nur Muster aus ihren Trainingsdaten. Aber das macht Bias nicht weniger problematisch.
Was ist Bias bei LLMs?
Einfaches Beispiel:
Prompt: "Der Arzt kam ins Zimmer. Er..."
LLM: "...oeffnete seine Tasche und holte das Stethoskop heraus."
Prompt: "Die Krankenschwester kam ins Zimmer. Sie..."
LLM: "...laechelte freundlich und prüfte die Vitalwerte."
Das Modell reproduziert Stereotype: Aerzte männlich/sachlich, Pflegekraefte weiblich/emotional.