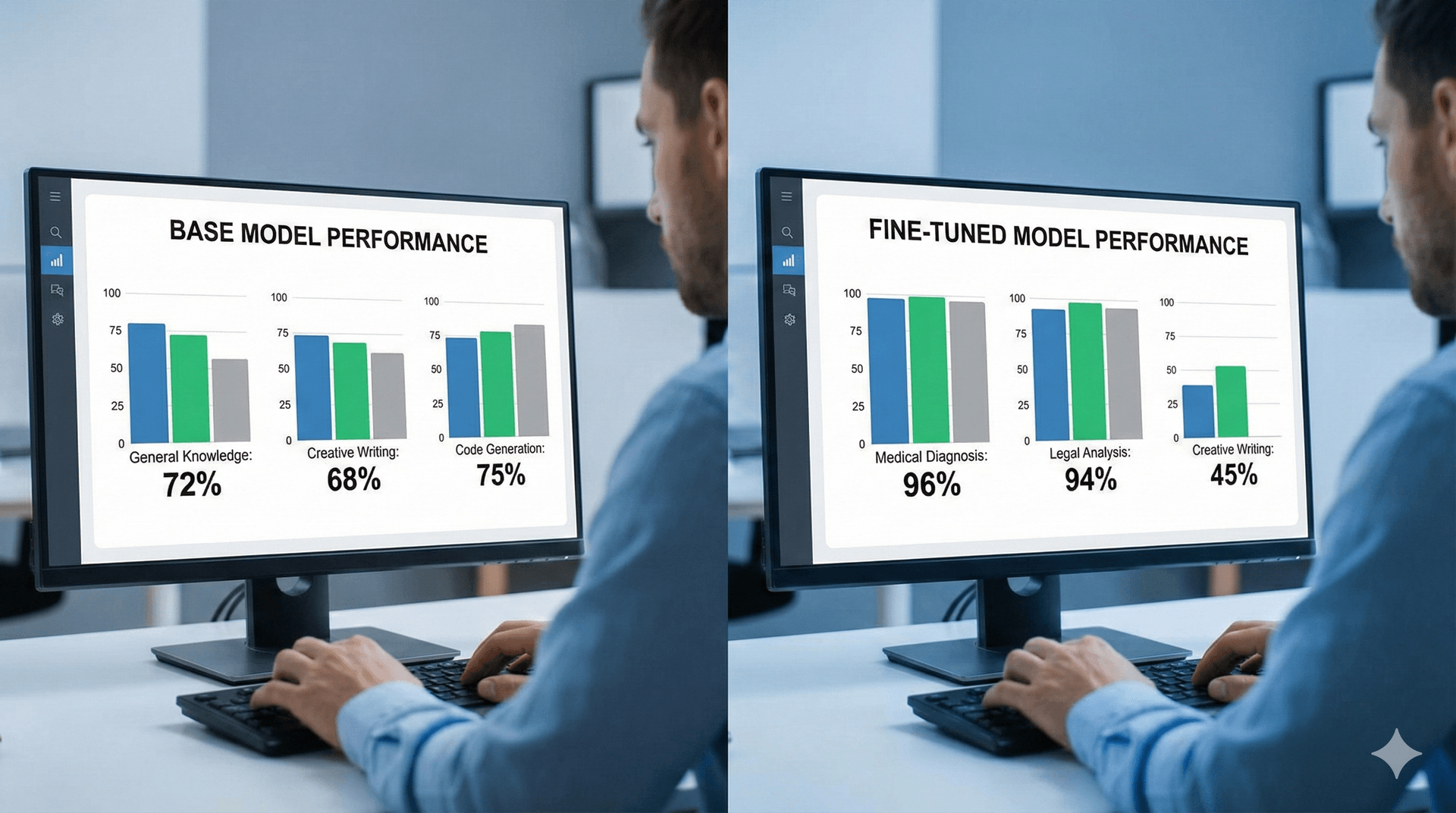
Executive Summary
Fine-Tuning bedeutet, ein vortrainiertes LLM mit Ihren eigenen Daten weiterzutrainieren. Das Modell lernt spezifische Muster, Styles oder Domänenwissen, das über sein ursprüngliches Training hinausgeht.
Wann sinnvoll: Fine-Tuning ist ideal für Style/Konsistenz, spezifische Formate und Domänenwissen. Für faktisches Wissen ist RAG oft die bessere Wahl.
Was ist Fine-Tuning?
Fine-Tuning ist wie ein Spezialisierungskurs für das Modell - es wird Experte für Ihre Aufgabe. Das Modell lernt aus Ihren Beispieldaten, wie es sich verhalten soll.
Ohne Fine-Tuning (Standard-Prompting):
Sie: "Schreibe eine Produktbeschreibung für Blaue Sneakers."
GPT: [Generische Beschreibung, variiert jedes Mal, nicht Ihr Brand-Voice]Mit Fine-Tuning:
Sie: "Schreibe eine Produktbeschreibung für Blaue Sneakers."
Fine-Tuned Model: [Perfekt im Stil Ihres Shops, konsistent,
nutzt Ihre Fachbegriffe, folgt Ihrem Format]