Executive Summary
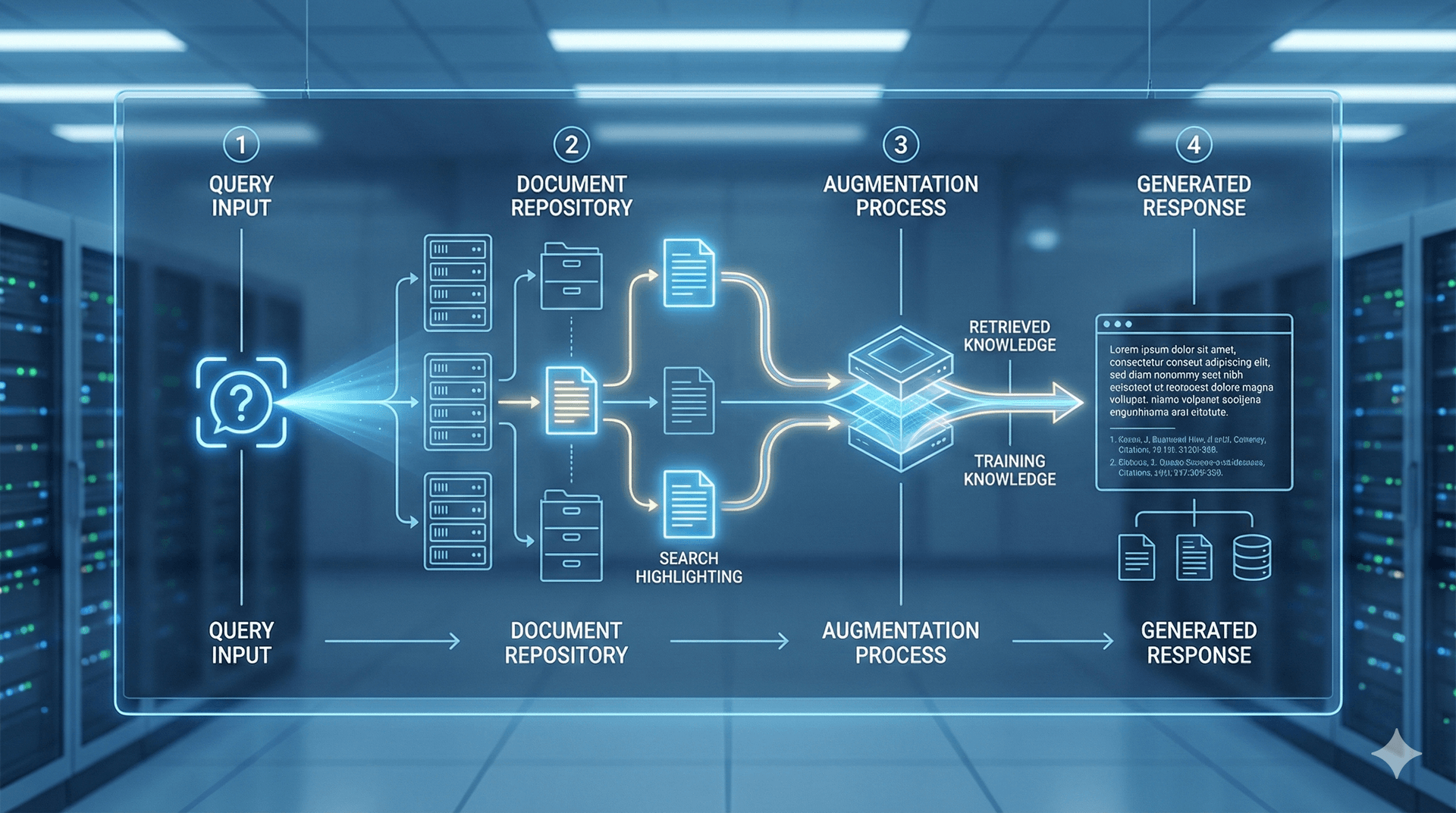
Retrieval Augmented Generation (RAG) ist eine Technik, bei der ein LLM nicht nur auf sein Trainingswissen zurückgreift, sondern zusätzlich relevante Dokumente abruft und diese als Kontext für die Antwort nutzt. Das Modell "liest" zuerst externe Quellen, bevor es antwortet.
Warum wichtig: RAG reduziert Halluzinationen drastisch, ermöglicht Zugriff auf aktuelle Informationen und macht Antworten durch Quellenangaben nachvollziehbar.
Was ist RAG?
RAG kombiniert Information Retrieval (Dokumentensuche) mit Generation (LLM-Antwort) - daher der Name. Statt sich nur auf Trainingswissen zu verlassen, sucht das System zuerst in einer Dokumentenbasis nach relevanten Informationen.
Klassisches LLM (ohne RAG):
User: Wer hat die letzte Wahl in Österreich gewonnen?
LLM: [Halluziniert oder veraltet, da Trainingsdaten begrenzt]Mit RAG:
1. System sucht in aktueller Wahlberichtsdatenbank
2. Findet relevante Artikel: "ÖVP gewinnt mit 28%..."
3. LLM erhält Artikel als Kontext
4. LLM: "Laut den aktuellen Wahlergebnissen..."